







Introduction
In today’s data-driven world, organizations face the challenge of managing and analyzing large amounts of data from different sources. To overcome this challenge, the concept of a data lakehouse has emerged as a powerful solution.
This article will explore how we leveraged Google Cloud Platform (GCP) technologies to build a robust data lakehouse. Our architecture includes GCP services such as Datastream, GCS, BigQuery (Biglake), Cloud Composer, Dataproc, Dataplex, and Data Catalog.
What is a Data Lakehouse?
A Data Lakehouse is a unified and scalable data platform that combines the best of data lakes and data warehouse.
Architecture
The top-level architecture of Data Lakehouse:
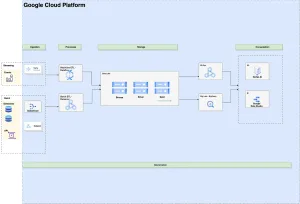
Lakehouse Components
The data lakehouse is composed of the following components:
Ingestion: Capturing and importing data from different sources into the data lakehouse for real-time or batch processing.
Processes: Applying data transformations, aggregations, and analytics to get valuable insights from the data within the data lakehouse.
Storage: Providing a reliable and scalable storage layer to store large volumes of structured, semi-structured, and unstructured data in its raw and processed forms.
Consumption: To retrieve and analyze data from the data lakehouse using various tools and technologies such as SQL queries, serverless applications, business intelligence (BI) tools, and machine learning (ML) applications.
Governance: Establishing policies, procedures, and controls to ensure data quality, security, privacy, and compliance within the data lakehouse. This includes managing metadata, access controls, data lineage, and auditing capabilities.
Organizing Data in a Data Lakehouse
To organize data in our lakehouse, we follow Medallion Architecture which is a systematic approach to logically organizing data within a Data Lakehouse. It follows a standardized structure comprising three main layers, namely Bronze, Silver, and Gold.
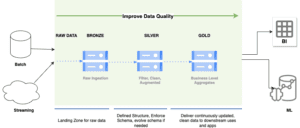
Bronze Layer:
- It acts as a landing zone for the Data Lakehouse.
- Raw, unprocessed data is stored in the Bronze Layer.
- In bronze, data is ingested from various sources without any transformation.
- Data is stored in its raw form, making it easy to trace back to its source.
- It provides a comprehensive and historical view of the data.
Silver Layer:
- The Silver Layer is a curated and transformed version of the raw data.
- Data from the Bronze Layer is processed, cleaned, and standardized.
- This is a cleaned version of Raw Data.
- Data quality checks and validation are performed to ensure accuracy.
Gold layer:
- The Gold Layer represents refined and business-ready data.
- The Gold Layer contains aggregated, summarized, and pre-calculated data for efficient querying and analysis.
- It is optimized for specific use cases and analytical purposes.
- Advanced analytics, machine learning, and data modeling are performed on the data in the Gold Layer.
- Data in the Gold Layer is often delivered through business intelligence tools, dashboards, or data APIs for consumption by end-users.
Implementation of Google Cloud services
We have implemented a data lakehouse on the Google Cloud Platform (GCP) using the following technologies:
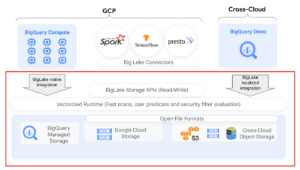
- Datastream: CDC for real-time data ingestion from DBMS
- Cloud Storage (GCS): For low-cost storage, this is the main storage of our Data
- BigLake: Storage engine that unifies data warehouses and data lakes
- Cloud Composer: For orchestration of data pipelines
- Dataproc: Managed Spark/ Hadoop clusters for data processing
- Dataflow: Real-time data processing from Google Pub/Sub
- Dataplex: For data management and governance
- Data Catalog: For metadata management
Benefits of Data Lakehouse:
Implementation of Data Lakehouse has some benefits which include:
Unified Data Storage: A data lakehouse provides a unified storage solution for various types of data, making it easier to manage and analyze all data in one place.
Scalability: It can easily scale to handle large volumes of data as our business grows, ensuring smooth data management without compromising performance.
Flexibility: A data lakehouse supports diverse data types, including structured, semi-structured, and unstructured data.
Data Exploration and Discovery: With a data lakehouse we can use various tools for data exploration and analytical purposes.
Cost-Effectiveness: By utilizing cloud-based resources and optimized data storage techniques, it is a cost-effective solution for storing and processing data.
Real-Time and Batch Processing: It allows for both real-time and batch processing of data, ensuring timely analysis of streaming data while also handling large-scale data processing tasks.
Advanced Analytics and Machine Learning: With a data lakehouse, we can leverage advanced analytics techniques and apply machine learning algorithms to extract meaningful insights and predictions from the data.
Data Governance and Security: A data lakehouse provides robust data governance and security features, allowing us to control data access, enforce privacy policies, and maintain data integrity and compliance with regulations.
Conclusion
We have successfully built a data lakehouse on the Google Cloud Platform. The lakehouse provides a unified platform for storing, managing, and analyzing data. It is scalable, secure, and cost-effective. We are confident that the data lakehouse will help us to make better decisions and improve our business.

