







Hi, I’m Cas Diependaal and I’m the Head of Platform Engineering over at ZEALS.ai. Data is involved in a lot of processes of our company and is basically a pillar for all the activities and business operations within ZEALS.ai. However, sadly, when it comes to storage, data is usually seen as a chokepoint.
A couple of years ago the people at ZEALS.ai set out to make an interactive chatbot application. Over the course of our growth, many features have been added to this application, but the core design has never changed. With the addition of these features and services, an ecosystem grew around our old application model.
This application model was also reflected in our database. Our database at first was only used as a storage for a web application, but eventually also had to store objects for applications and services who wanted to communicate with our core web application. Add to this that our application was originally written in Ruby on Rails with ActiveRecords, so you can see where this story takes us.
The first thing I did when I arrived at ZEALS.ai was make an EER-diagram of our largest (relational) database to make sense of the application, and it was a monster:

In this image it’s easy to see the effect of growing an application without reworking the architecture to fit with your growth. The relationship between our tables are so intricate that no one dared to touch the database because they didn’t know what would break if relationships were removed. Furthermore simple operations in our application started to need many joins and writing and reading of new information became slow.
Now all of this isn’t completely the database’s fault. Our application wasn’t designed for our growth to start with, so it was obvious that at one point we needed to redesign. However the current state of our database does complicate things when we want to split our monolith into microservices. As usual the big question is: Where do we even start?
Well, usually the answer to this question is something different than what we chose to do. The first lines of Martin Fowlers’ article about big tech changes (https://martinfowler.com/articles/patterns-legacy-displacement/) is that it usually all goes wrong when a company decides to undertake a multi-year project to rework the current architecture. Our advantage in comparison to other companies is that we’re not building a system to respond to a real world concept. We’re not a webshop that has to replicate how business processes happen in the storage and warehousing facilities. ZEALS.ai is creating a chatbot platform, and because we’re building a platform which only exists in the tech world we have free reign over how we and our sales departments want to operate.
We do realize this is quite an assumption, so this might come back to bite us eventually.
What we failed to realize at the start of our company, but what we do know now is that our system is mostly event-based. Conversations that a chatbot has are usually a response to a certain event happening. What we needed to figure out is exactly where we can split our monolithic app so that we can apply decoupling on some key areas and replace the app with a network of microservices. To identify these domain, we decided to do Event Storming.
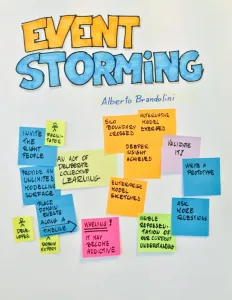
What event storming specifically is, is written in a lot of books by Alberto Brandolini (https://www.eventstorming.com/). What it basically comes down to is that you try to identify, by going chronologically through your system, what events happen in your business process. Each event can then be related to new events, actors and system interactions. The important part is that you usually do workshops like this by mixing tech and business people so that you can figure out exactly where there’s a difference in perspective.
For Event Storming you don’t need much. Preferably, you need a physical space, but as an international company that was a bit hard to do. Instead what we did was grab a Miro board called ‘Event Storming by Judith Birmoser’ where we could all cooperate on an Event Storming workshop at the same time. We had one person guide the Event Storming process and another keeping track of the more content-related issues, like naming events that might not actually take place or prevent people from diving too deep into the technique.
For us at ZEALS.ai the Event Storming workshop was split into two groups to make things more manageable. We invited people from the frontend, backend, infra and business side to figure out exactly what events happen in our process. They were asked to write down all the events they could think of and order them chronologically from left to right. However, instead of describing events about the current, overcomplicated system, we asked people to define events in what would be in their ideal system. This turned out to be a mistake because everyone had such different ideas about how things should work, that we ended up with way too many events to explain.
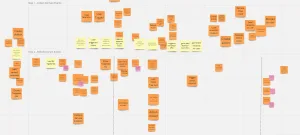
Our second attempt we dumbed things down a bit. What we wanted to know from people was the events that happen in the current system when considering a chatbot in general. This means what interactions does our system have + what interactions does a chatbot have in general. This gave us much more valuable information about our system, because we now got a list of events that we currently have and found out about a lot of events we should be doing. After day 2, we were able to create a chronological chain of events and figure out what our core business loop was. It was also a lot easier for us to realize some simple stuff we’ve been overlooking for years: our system isn’t that complicated.
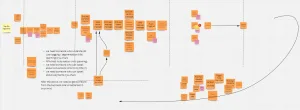
For day three, we asked some experts from the business side to join in to confirm if what we made up until now correlates to what they’re doing every day and how they want it to work. By the end of day three, we were able to split up all our events into different domains and define how these domains interact with each other. We were able to realize that we need, for example, a new domain specifically to deal with users, and that our business teams are doing a couple things manually that our system should’ve been taking care of.

In the end after three days of workshopping with about 20 people, our Event Storming workshops were a great success. Using the workshops we managed to tackle a daunting task (breaking a part a huge monolith) and make it a fun and educational process for all the people involved. Currently, we’re using the domains we discovered during our workshop to build a new architecture with a proper decoupling and all our architects are in agreement that we’re now going in the right direction.
Here’s a couple lessons learned from Event Storming:
- Our core application loop is pretty short.
- Some of our core functions should be decoupled because it didn’t make sense at all for them to be interconnected.
- What seemed like a huge process to split up the relational database turned out to be simpler than we thought because our domain can mostly be easily clearly defined.
- Sometimes you need to do things a bit differently than what they’re described to achieve a result that better fits with your goals and mindset.
- It’s usually better to have people build something together (in a workshop) than to have everyone build their own thing separately.
I hope that by sharing this experience, including my key takeaways and explanation of what worked for us to learn more about our database and system, it will also be beneficial for you.

